
")
编者按:
本文转载于公众号:戴老师的CG日常
作者:戴巍
如需转载请与原公众号或原作者联系。
前面在 SD 里做 Raymarching 的部分,涉及到大量节点的复制,对于某些比较懒的人来说,复制节点是比较烦人的事情,希望可以做到工具化解决。
这当然是 ok 的,在 SD 的 python api 不断更新下,我们在 SD 里写代码可以解决的问题越来越多了。
这一篇文章里,我将给大家介绍一些,SD 中写代码的常用套路、基本功能的实现方法。
最后我们做一个批量复制节点并能相互连接的小脚本。
学完之后就可以根据自己的需求做一些批量化操作的小脚本了。
学习本教程至少需要对 python 语言有基本的运用能力,对SD软件的基本功能还是要熟悉。
本文的功能全部都是基于 Substance Designer 2019.1.2 版本。
目录:
- 在 vscode 中设置自动补完
- 获取当前选中并移动位置
- 创建 atomic 节点
- instance 节点和 atomic 节点的本质区别
- 创建 instance 节点
- 改节点参数
- 连接属性
- 批量复制与连接
在 vscode 中设置自动补完
我使用 vscode 来编写 SD 的代码,操作会舒服很多,别的 IDE 理论上是一样的。如果你不习惯用 IDE,也可以直接在 SD 的 python 面板里编写,不过操作会繁琐很多,而且没有自动补全,可能会稍微有点痛苦。
首先F1 输入settings ,打开user settings
搜索 auto complete 点这个 edit in settings.json
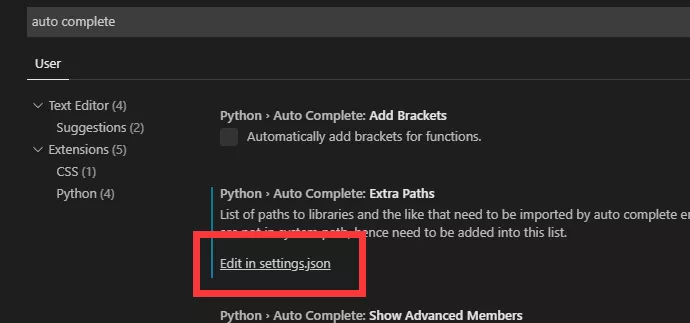
在 json 文件最后多加一个路径

“python.autoComplete.extraPaths”: [
“(你的安装目录前半段)Substance Designer 2019\\resources\\python”]
这样,vscode 就可以读取 SD 官方写好的 python 库里的代码进行自动补完。
新建一个 python 文档,然后输入以下代码。
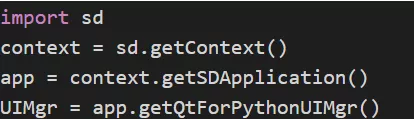
import sd
context = sd.getContext()
app = context.getSDApplication()
UIMgr = app.getQtForPythonUIMgr()
import sd 当然就是导入sd的 python 代码模块了。之后的 context app 都不用管是什么,我们最后是要获取 UIManager 类,后续的很多操作都非常依赖这个类。这三行代码也是在SD里写工具的起手式,不管干什么,先把这三行挂上。
获取当前选中并移动位置
从最简单的获取当前选中节点开始。
UIMgr已经包含了获取当前选中的函数:
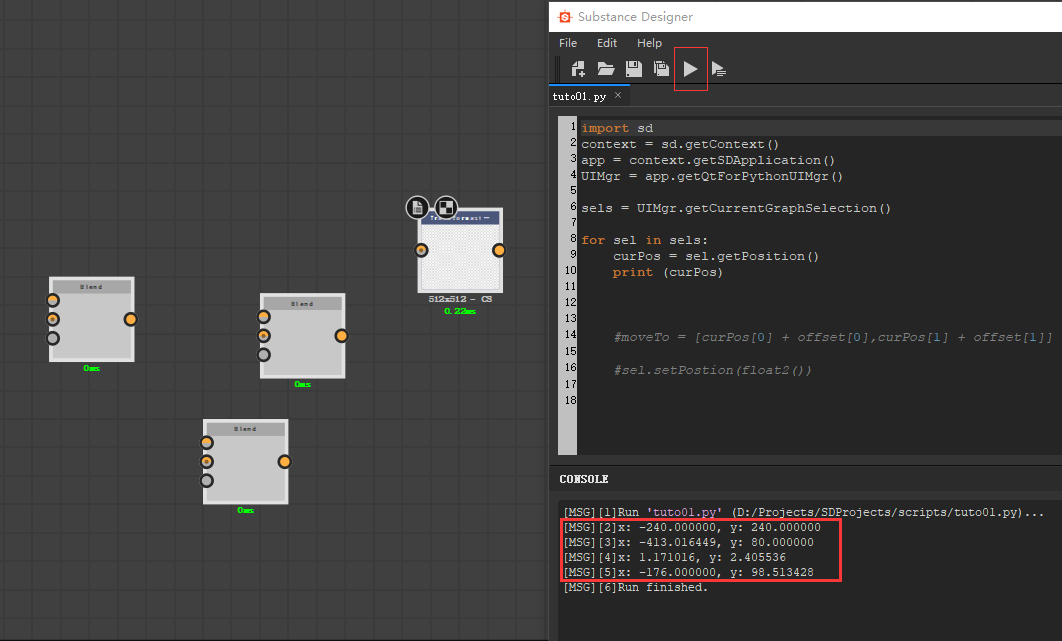
sels = UIMgr.getCurrentGraphSelection()
对于选中的每一个节点,我们对节点进行移动操作。首先要获取这个节点当前的位置。没一个 sel 都是一个 node 类,这个 node 类里有很多函数可以调用,比如说 getPosition()顾名思义,就是获取节点当前位置的函数。我们打印一下获取的位置看看。
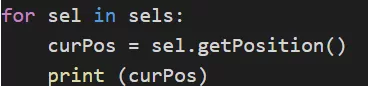
for sel in sels:
curPos = sel.getPosition()
print (curPos)
在SD的python 面板中,点击打开按钮,打开我们刚才在vscode中编写的python文件,然后直接点后面的播放按钮执行。
对于选中的这些节点,就可以打印出他们的坐标信息了。
接着我们要开始着手操控这个SD的节点世界,先从最简单的开始,让他们改变自己的走位!
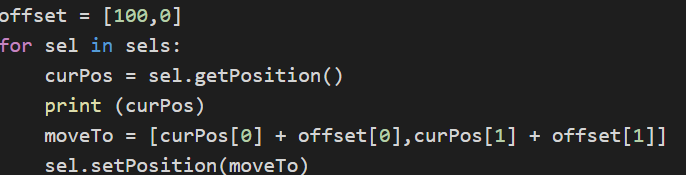
offset = [100,0]
for sel in sels:
curPos = sel.getPosition()
print (curPos)
moveTo = [curPos[0] + offset[0],curPos[1] + offset[1]]
sel.setPosition(moveTo)
我们定义一个 offset 变量来控制节点位移的偏移量。
用当前的位置的x加上 offset 的x,y也同理,获得新的 moveTo 变量;就是我们要的终点位置。
sel是个 node 类,上面有个 setPosition 函数,就是控制节点位置的。我们写好这些,执行。
然后就报了一个 type error
[ERR][9]_res=self.mAPIContext.SDNode_setPosition(self.mHandle, ctypes.byref(position))
[ERR][10]TypeError
[ERR][11]:
[ERR][12]byref() argument must be a ctypes instance, not ‘list’
意思说 setPosition 函数的输入,应该是一个 ctypes instance 而不是一个 list。
这里我们就需要知道一个知识,SD里所有的修改参数操作,输入的变量类型,都必须是SD自己定义的一套,而不能按照我们的直觉胡来。
这里我们输入的变量是一个二维向量,我们要导入SD自己的二维向量类型来用。
from sd.api.sdbasetypes import float2
在文件的开头输入以上代码,导入SD的 float2 类型。然后我们把 moveTo 变成一个float2类型的变量,输入的x和y是原来的x和y的参数。内容是一样的,只有变量的类型改变了,原来是一个list类型,现在是一个SD自己的 float2 类型,让函数可以识别。

moveTo = [curPos[0] + offset[0],curPos[1] + offset[1]]
moveTo = float2(moveTo[0],moveTo[1])

创建atomic节点
因为SD中有三种 graph,一般我们最常用的那种叫 compositing graph,然后 pixel processor 里面有很多函数的那种叫 function graph,还有 fxmap节点里面的叫 fxmap graph。
进入不同的 graph 以后相当于进入了不同的世界。我们如果想要创建一个节点,首先是要知道现在我们进去的是哪一个 graph,然后再在这个 graph 里进行相应的操作。
获取 graph 的操作也是通过 UIMgr 类来实现的:
thisGraph = UIMgr.getCurrentGraph()
这样 thisGraph 里就是我们现在正在使用的 graph 类,这个类也有很多的函数。我们在 help→python api documentation 里可以找到这些信息:
搜索 compgraph 就可以找到 compgraph 类的页面
然后可以使用的函数里,有个名字叫 newNode 的,一看名字就知道是我们想要用的函数。

但是这个函数的输入是 sdDefinitionId(string),意思是说,要输入一串字符串来创建节点。那么这个字符串到底是什么东西,我们要怎么查呢?
在帮助文档的这个 Modules Definitions 页面中,我们可以查到很多和节点相关的信息。


这些就是可以创建节点使用的具体字符串了。
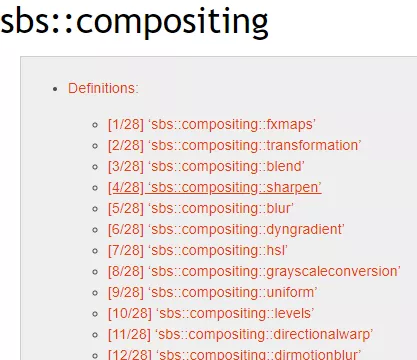
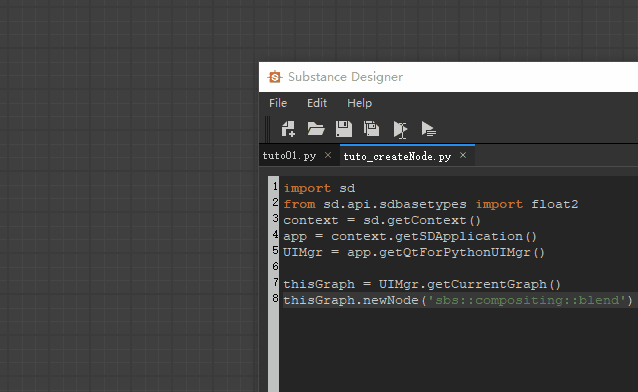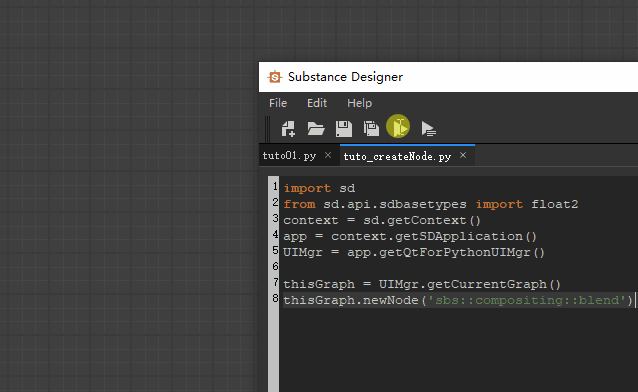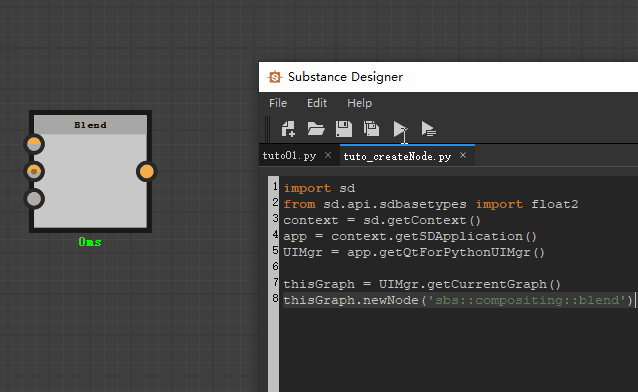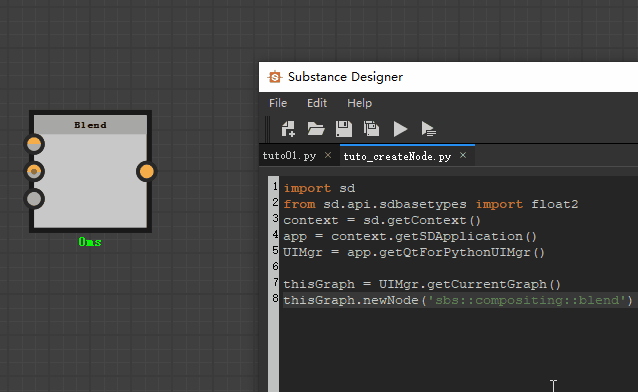
比如我们要创建一个blend节点,代码就可以这样写:
thisGraph = UIMgr.getCurrentGraph()
thisGraph.newNode(‘sbs::compositing::blend’)
instance和atomic节点的本质区别
在我们用上面方法创建节点的时候,会发现一件事。就是有一些我们常用的节点,并不在官方提供的这一份榜单中。
比如slope blur节点,blur hq节点,cloud2节点 以及一系列程序纹理节点。那我们想要创建这些不在榜单中的节点该怎么办?
这里我们要理清一个概念。
在SD这个软件中,节点还是分两种大类型的。一种是所谓的 atomic nodes,在节点创建面板中可以找到这些节点。
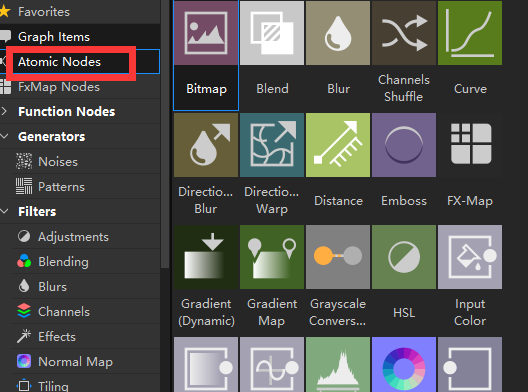
除了 atomic nodes 以外的节点,都是 instance 类型的。这两种节点有什么区别呢?
正如名称的暗示,atomic node 是原子节点,是最小节点组成,是无法再被拆分的节点。而其余的instance 节点,可以通过 ctrl+e(或者右键open reference),一层一层往里拆,看到内部的所有构成,你最终会发现它们全都是有 atomic node 构成的。

cloud2 节点的内部,全都是 fxmap blend levels output 这些 atomic 节点。

所以说,虽然有很多 instance 节点是官方制作的,但是我们在SD里区分节点不能按照来源是来自官方或者第三方个人来区分,因为对于软件本身来说,所有的 instance 节点都没有本质区别,都是由各种 atomic 节点通过不同的方式组合而成的。
唯一的区别可能是,官方自己做好的这些 instance 节点,放在安装包里,每次安装的时候,自动解压好了给我们用而已。而我们自己做的所有节点都是 instance 节点,和官方做的 instance 节点没有本质区别,只是不在官方的安装包里而已。
并且我们可以在硬盘上看到所有官方做的 instance 节点,还可以删除它们,或者在这个位置放一些我们自己做的 instance 节点,都是可以的。
我们选中一个官方做的 instance 节点,点击 package 右边的打开图标,可以在硬盘上看到这个节点的sbs文件。
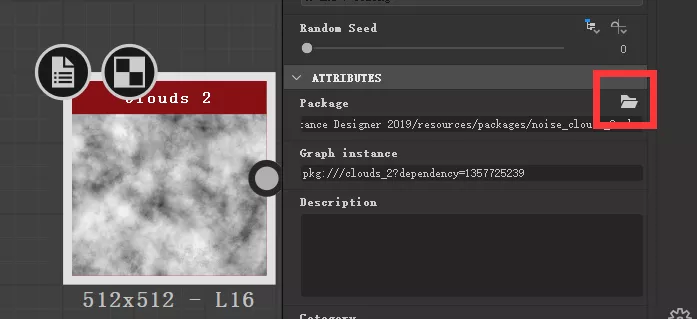
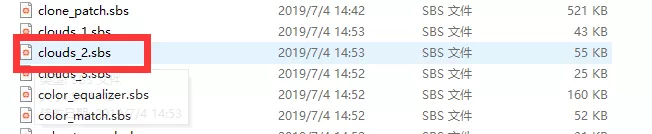
而在 atomic 节点上是没有这些东西的。
所以通过 python api 创建这些 instance 的方法和 atomic node 的方法是截然不同的。
下面我们介绍用 python api 创建这些 instance 节点的方法,这种方法可以创建官方做的 instance 节点,也可以创建我们自己做的节点。
创建instance节点
对于一个 instance 节点来说,他必然存在于某一个 .sbs 文件中。所以我们首先要知道这个sbs文件的具体位置。
这里有两种情况,如果是我们自己创建的 instance 节点,那么储存的位置我们自己是知道的,复制字符串就可以了。如果是官方做的节点,我们虽然可以直接拷贝位置的绝对路径,但是插件在别人电脑上运行的时候,他使用的路径可能跟我们不一样。
那么我们获取官方做的 instance 节点,就需要通过代码来获取它的相对位置,确保代码执行的时候,在所有人的电脑上运行,都可以找到想要找的节点的位置。这个也是套路,大家直接背方法就行。
首先导入一个 SDApplicationPath 类,这里记录了一些SD路径相关的信息,我们通过这个东西来获取SD安装路径下的 resources 文件夹的路径。
from sd.api.sdapplication import SDApplicationPath
resourcePath=app.getPath(SDApplicationPath.DefaultResourcesDir)
然后所有装 instance 节点的sbs文件,都在 resources 里面的 \packages 文件夹中。

所以具体的某个sbs文件的路径,就是:
os.path.join(resourcePath,’packages’,fileName)
这个是 python 的os库,是跨平台对系统的路径之类的东西进行操作的好东西,用的时候记得 import os。
os.path.join 意思是把后面输入的东西,比如说(a,b,c,d)按照 a\b\c\d这样的方式,在变量之间插入‘\’字符变成路径。并且具体插入的规则符合不同操作系统的规范,一般处理路径的时候都按照这个方法去搞。
其中 fileName 是这个 sbs 文件的全称,比如 ‘clouds_2.sbs’ 或者 ‘slope_blur.sbs’ 这样。
也就是说完整的返回的路径一般是这样的:
C:\SteamLibrary\steamapps\common\SubstanceDesigner2019\resources\packages\slope_blur.sbs
我们最后要获得的就是这么一行字符串,这是文件的具体路径。
文件找到了以后,我们就要调用这个文件。调用某个 .sbs 文件的时候,我们需要用到一个SD自己的库,叫 PackageManager,是专门管理这些sbs文件的。
然后用这个 packageManager 中的 loadUserPackage 方法读取具体的某个 sbs 文件,输入的变量就是之前获取的路径。

pkgMgr = app.getPackageMgr()
package=kgMgr.loadUserPackage(os.path.join(resourcePath,’packages’,’slope_blur.sbs’))
这样,我们就打开了想要的 sbs 文件了.
但是还是没有创建任何节点。
这是因为,一个 sbs 文件中可能有很多个 graph,我们每个节点都其实是一个 graph。我们光读 sbs 文件是没有用的,sbs文件本质是上一个 graph 文件的打包。
所以我们要具体调取这个 sbs 文件中的某个 graph,还要继续添加代码:
graph=package.findResourceFromUrl(‘slope_blur’)
变量 package 是我们在SD中打开的这个 slope_blur.sbs 文件,findResourceFromUrl()函数输入的是,这个 sbs 文件中某个 graph 的名字。然后就可以返回这个具体的graph。
最后,我们要在某个现在我们正在使用的 graph 面板中,创建一个包含这个 graph 的 instance node。
thisGraph.newInstanceNode(graph)
这样,就可以创建 instance 节点了。
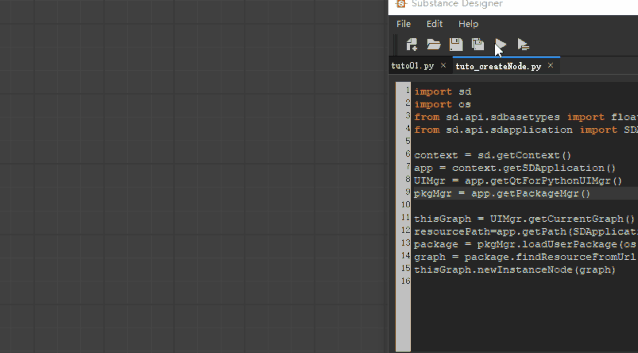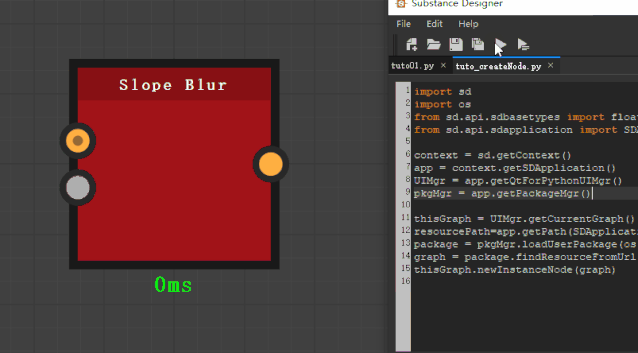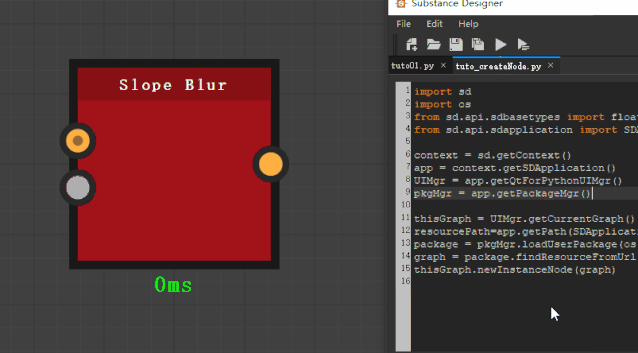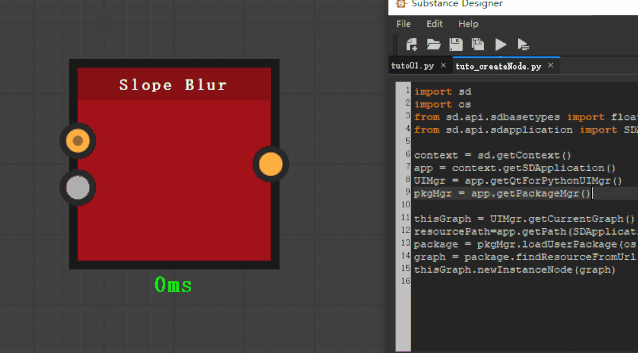
最后完整代码如下:
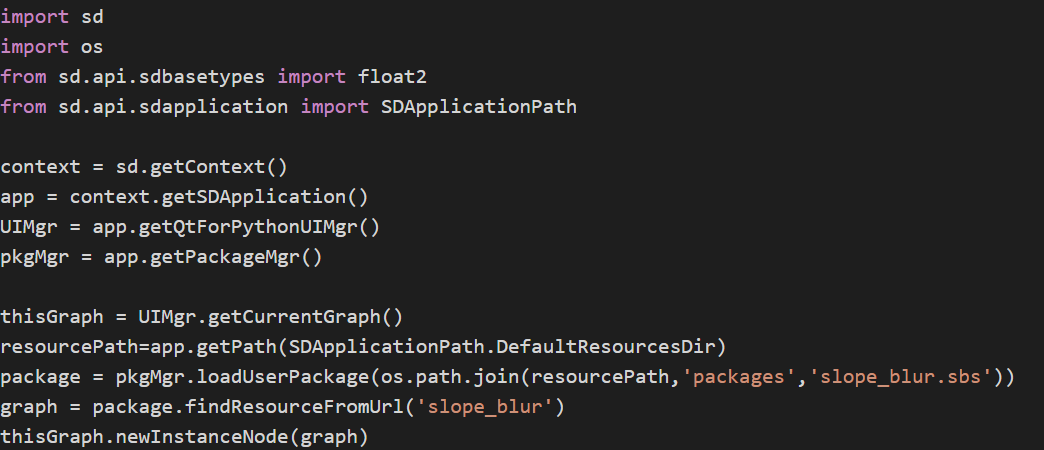
import sd
import os
from sd.api.sdbasetypes import float2
from sd.api.sdapplication import SDApplicationPath
context = sd.getContext()
app = context.getSDApplication()
UIMgr = app.getQtForPythonUIMgr()
pkgMgr = app.getPackageMgr()
thisGraph = UIMgr.getCurrentGraph()
resourcePath=app.getPath(SDApplicationPath.DefaultResourcesDir)
package=pkgMgr.loadUserPackage(os.path.join(resourcePath,’packages’,’slope_blur.sbs’))
graph = package.findResourceFromUrl(‘slope_blur’)
thisGraph.newInstanceNode(graph)
这部分稍微有点繁琐,我总结一下关键点。对于创建 instance 节点来说,核心的东西就两个:
- 这个sbs文件的路径
- 想要创建的节点的 graph 名字
知道了这两个信息就可以完全确定要创建的节点到底是什么,其余的就是按代码格式进行操作了。
另外,有一些比较复杂的 sbs 文件里,可能有文件夹,比如说官方自己做的 functions.sbs。
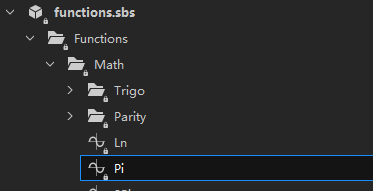
如果我们要创建一个Pi节点。
需要把 findResourceFromUrl()的输入变量改成 ‘Functions/Math/Pi’

resourcePath=app.getPath(SDApplicationPath.DefaultResourcesDir)
package=pkgMgr.loadUserPackage(os.path.join(resourcePath,’packages’,’functions.sbs’))
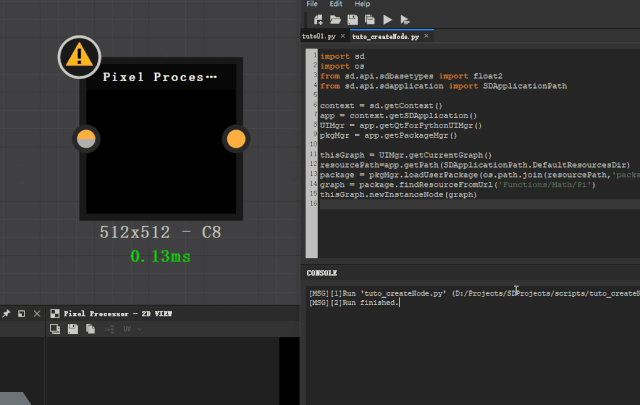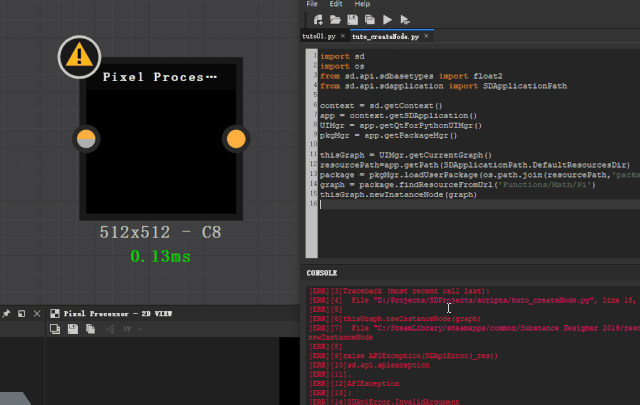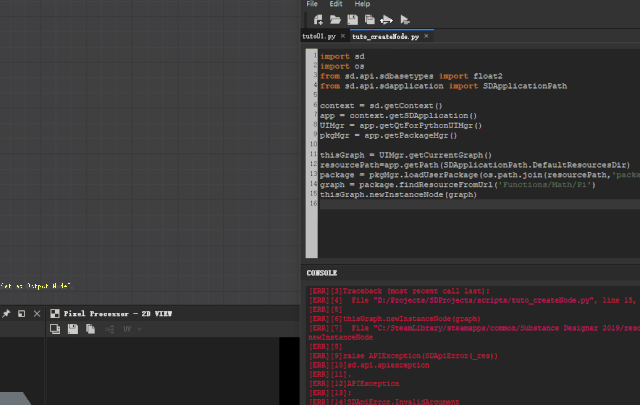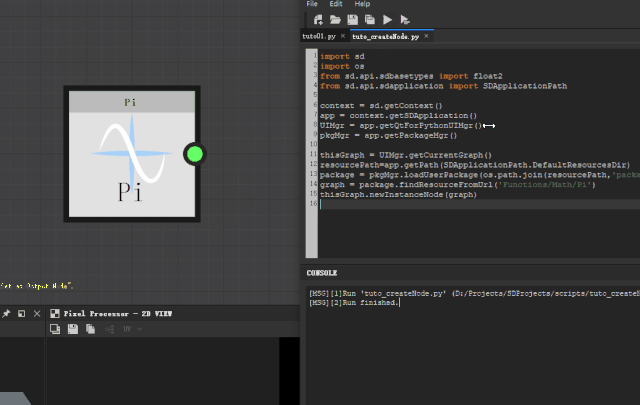
graph = package.findResourceFromUrl(‘Functions/Math/Pi’)
thisGraph.newInstanceNode(graph)
这个节点只能在 functionGraph 中使用,所有我们要进入一个 pixel processor 节点的 graph 运行代码,在 compGraph 中会报错。
改节点参数
想要改变节点上的某些参数,首先我们要知道需要改变参数的属性是什么。
这就涉及到SD中的 SDProperty 类了,这个类代表的就是节点上的各种属性。

帮助文档上,node 类中,有一个 getProperties 函数,可以 get 到某个节点的各种属性。但是要输入一个 SDPropertyCategory 的东西,这个东西是一个枚举,其实主要就是用这个枚举的 Input 和 Output来决定,我们要查阅的是这个节点的输入端的属性,还是输出端的属性。
要调取 propertyCategory,我们就要先导入这个类:
from sd.api.sdproperty import SDPropertyCategory
然后对于选中的某个节点,我们获取它的input属性:
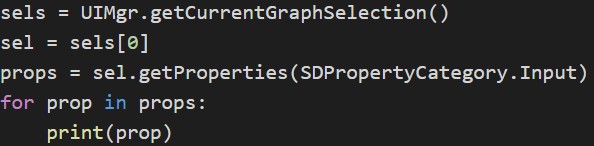
sels = UIMgr.getCurrentGraphSelection()
sel = sels[0]
props = sel.getProperties(SDPropertyCategory.Input)
for prop in props:
print(prop)
然后打印每个属性来看看是什么东西:
[MSG][1]Run’tuto_changeProp.py’ (D:/Projects/SDProjects/scripts/tuto_changeProp.py)…
[MSG][2]<sd.api.sdproperty.SDProperty object at 0x000002428B49D780>
[MSG][3]<sd.api.sdproperty.SDProperty object at 0x000002428B49D860>
[MSG][4]<sd.api.sdproperty.SDProperty object at 0x000002428B49D780>
[MSG][5]<sd.api.sdproperty.SDProperty object at 0x000002428B49D860>
[MSG][6]<sd.api.sdproperty.SDProperty object at 0x000002428B49D780>
[MSG][7]<sd.api.sdproperty.SDProperty object at 0x000002428B49D860>
[MSG][8]<sd.api.sdproperty.SDProperty object at 0x000002428B49D780>
[MSG][9]<sd.api.sdproperty.SDProperty object at 0x000002428B49D860>
[MSG][10]<sd.api.sdproperty.SDProperty object at 0x000002428B49D780>
[MSG][11]Run finished.
结果返回的都是 SDProperty 的类,这样对我们人来说,没有可读性,我们想要获取的其实是属性的名字。那么我们在帮助文档里查询属性类,看看有没有返还他自己的名字之类的函数。在帮助文档搜到 SDProperty 页面:

这个函数应该就可以,我们改一下代码,print 这个id看看是什么:
for prop in props:
print(prop.getId())
[MSG][2]$outputsize
[MSG][3]$format
[MSG][4]$pixelsize
[MSG][5]$pixelratio
[MSG][6]$tiling
[MSG][7]$randomseed
[MSG][8]scale
[MSG][9]disorder
[MSG][10]non_square_expansion
[MSG][11]Run finished.
ok,这一次得到的东西,就是我们人能看得懂的了,是这个选中的 clouds2 节点的一些输入属性。
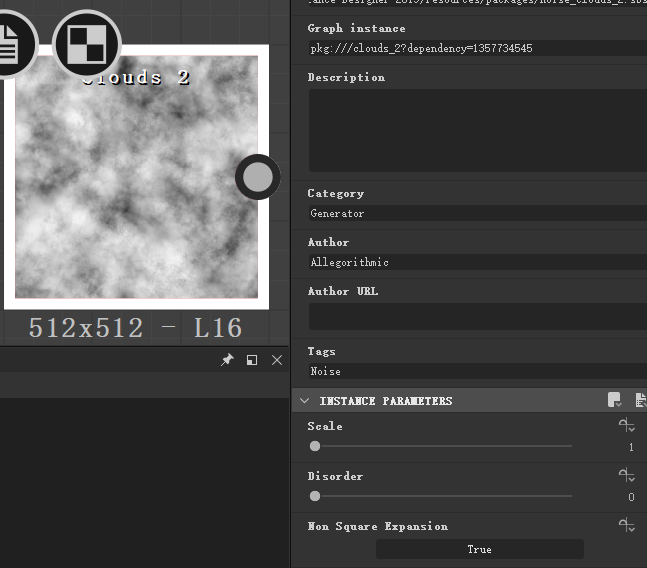
比如说我们要改他的 disorder 属性。我们查找了 node 类的帮助文档页面,找到一个应该可以用的函数:

这个函数需要输入两个参数,一个是 propertyId,就是我们刚才查到的那些名字,比如id里有一个disorder,就是我们要改的属性,然后要输入一个 sdValue;上次我们已经在改位置上吃了一次亏了,这一次还有没有问题,我们先不管,先按照直觉写一串代码试试水。
sel.setInputPropertyValueFromId(‘disorder’,0.5)
[ERR][17]_res = self.mAPIContext.SDNode_setInputPropertyValueFromId(self.mHandle, ctypes.create_string_buffer(sdInputPropertyId.encode(‘utf-8′)), sdValue.mHandle)
[ERR][18]AttributeError
[ERR][19]:
[ERR][20]’float’ object has no attribute ‘mHandle’
果然报错了,报了一个 attribute error,果然还是我们输入的值的类型有问题,不能输入 float 类型,很可能是要输入SD自己定义的 float 类型。
跟之前一样
from sd.api.sdvaluefloat import SDValueFloat
sel.setInputPropertyValueFromId(‘disorder’,SDValueFloat.sNew(0.5))
好了

你可能会注意和 setPosition 的时候有些不一样的地方,就是导入的类是 SDValueFloat,而且还用了一个 sNew 函数,而之前是从 sdbasettypes 导入的 float2。
这是因为SD里其实有两种完全不同的数据类型。从 sdbasetypes 导入的是一种。
from sd.api.sdbasetypes import
int2, int3, int4, float2, float3, float4, bool2, bool3, bool4, ColorRGBA

本质是ctype结构体。
另一种,是SD自己定义的一些数据类型,一层层往里扒,发现本质上是,SDAPIObject。
绝大多数的时候我们都是没办法直接使用 ctype 结构体的,除了少数像 setPosition 这种函数。大部分我们改某个属性的参数的时候,要求输入的都是 sdValue,就是我们介绍的下面这种,SD自己定义的东西。
这个东西的创建是有格式的,一般是
value = SDValueFloat2.sNew(float2(a,b))
value = SDValueFloat3.sNew(float3(a,b,c))
value = SDValueInt4.sNew(int4(a,b,c,d))
这是当你输入的类型是多通道的时候,sNew 函数的输入,需要用一个 ctype 类型的结构体,也就是float2(a,b)或者 int4(a,b,c,d)这种。这里用的 float2 或者 int4 都不是 python 默认类型,而是我们一开始就导入的 ctype 结构体。
而如果设置的值不是多通道的,则 sNew 输入的就是 python 自己的基本数据类型,不是 ctype 结构体:
value = SDValueFloat.sNew(2.8)
value = SDValueInt.sNew(4)
value = SDValueBool.sNew(True)
value = SDvalueString.sNew(‘test’)
当我搞明白这一切以后,就只有一个使用感受——恶心;但并没有什么办法,该怎么用还得怎么用。
反正感觉在 SD 里做插件,搞起来是很麻烦很慢。
连接属性
对于属性相关的操作,是 SD 中非常繁琐的一部分,大家做好心理准备。
在 SD 中做属性连接的逻辑是,在某一个 node 类上,调用一个函数,对另外一个节点的某个属性,创建 connection 类。这个 connection 类就是节点和节点之间的连线。
比如说,我们很有可能用的 newPropertyConnectionFromId 函数:

看函数的输入,我们需要确定三个东西,就是:
- 当前节点的输出属性id(string)
- 当前节点即将连接的节点(node)
- 即将连接的节点上将要连接的属性id(string)
这个从直觉上就非常容易理解。那么我们只要照着这三个输入去填值就行了。
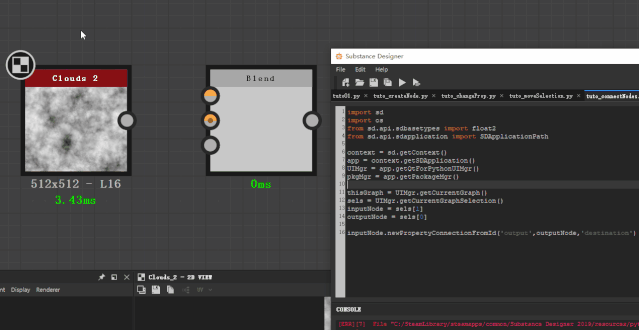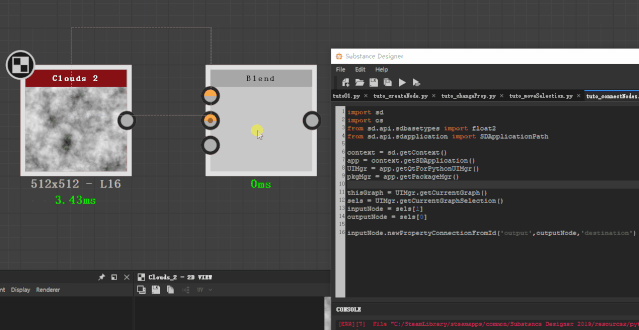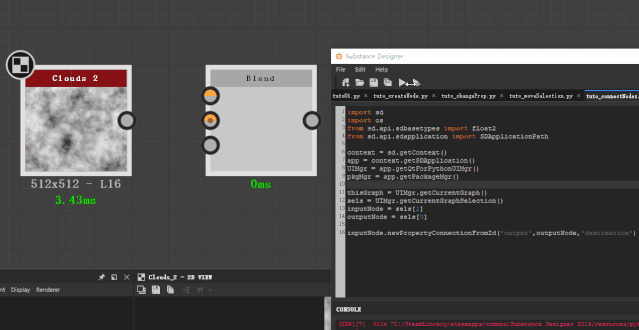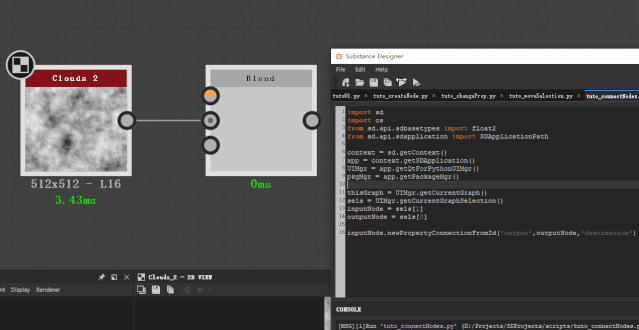
现在比如说,我要把一个clouds 2节点连到blend节点的background通道上面去。

为了简化问题,我会用选中这两个节点,然后通过 getCurrentGraphSelection 函数来获取这两个节点。
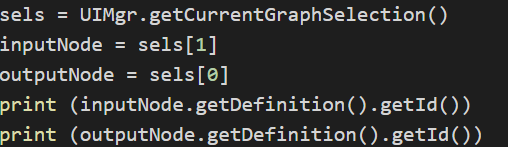
sels = UIMgr.getCurrentGraphSelection()
inputNode = sels[1]
outputNode = sels[0]
print (inputNode.getDefinition().getId())
print (outputNode.getDefinition().getId())
[MSG][1]Run’tuto_connectNodes.py’ (D:/Projects/SDProjects/scripts/tuto_connectNodes.py)…
[MSG][2]sbs::compositing::sbscompgraph_instance
[MSG][3]sbs::compositing::blend
[MSG][4]Run finished.
通过这些代码,可以确定 inputNode 就是我们选中的 clouds 2 节点,outputNode 就是 blend 节点了。
另外,someNode.getDefinition().getId() 是获取这个节点是什么节点的常用方法。
然后我们用 inputNode 对 outputNode 进行连接,两个节点我们已经确定,剩下就需要确认需要连接的两个属性的id了。
我们当然可以使用之前的方法,通过
someNode.getProperties(SDPropertyCategory.Input) 这样的方式,获得具体的属性类,再遍历属性类,用prop.getId()的方式获取这个属性的id。
但是这样比较繁琐,很多时候,我们是可以通过查表来查到这些属性id的。还是在 Modules Definitions 页面。
找到blend节点,可以看到下面有详细的输入属性描述。我们很容易就发现,background 通道的property id 就是 destinaition。

然后我们再尝试找到 cloud 2 节点的输出属性的id,但是这个节点是个 instance 节点,我们查不到。不过先不要急着用代码去查输出id,我们直接 ctrl + e 进到这个节点的内部,选中它的 output 节点,看到output 节点上有个 Identifier,这就是他的id:
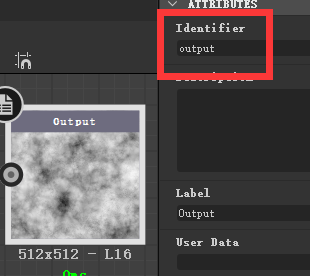
所以我们就用这样一串代码来连接两个节点,记得执行的时候要选中两个节点。
inputNode.newPropertyConnectionFromId(‘output’,outputNode,’destination’)
如果是别的 atomic node 的连接呢?我们不能进入节点内部看输出id,也不想用代码去查,最快的方式当然还是查表。而且查表的时候我们还发现一个规律——那就是所有的输出属性id,都叫做 ‘unique_filter_output’ 。
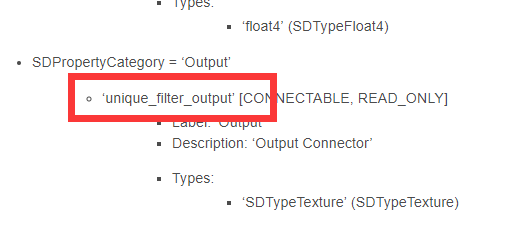
直接这么写就可以连上。
inputNode.newPropertyConnectionFromId(‘output’,outputNode,’destination’)
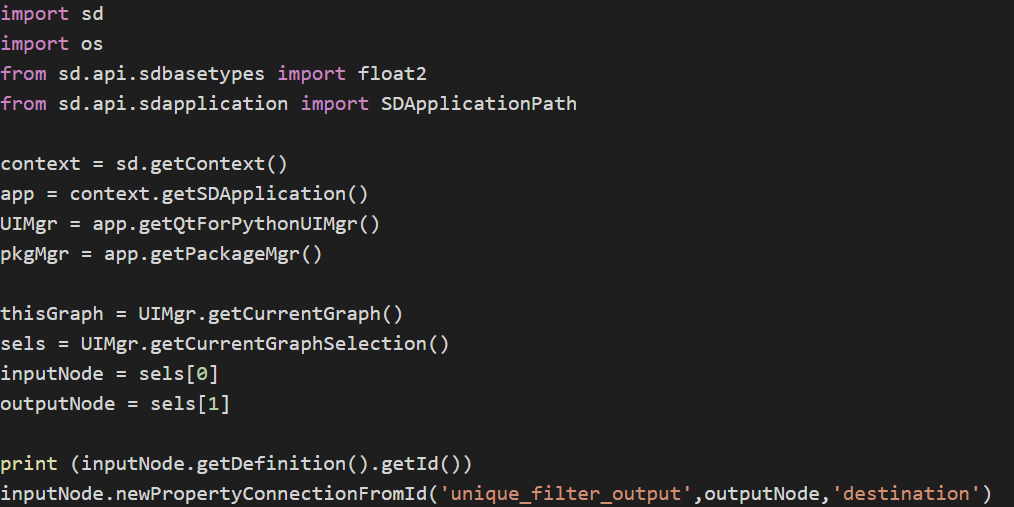
import sd
import os
from sd.api.sdbasetypes import float2
from sd.api.sdapplication import SDApplicationPath
context = sd.getContext()
app = context.getSDApplication()
UIMgr = app.getQtForPythonUIMgr()
pkgMgr = app.getPackageMgr()
thisGraph = UIMgr.getCurrentGraph()
sels = UIMgr.getCurrentGraphSelection()
inputNode = sels[0]
outputNode = sels[1]
print (inputNode.getDefinition().getId())
inputNode.newPropertyConnectionFromId(‘unique_filter_output’,outputNode,’destination’)
最后代码是这样。注意这个做法里为了取巧,用的 get 选中节点的方式来获取两个节点,所以一定要检查一下两个节点在 list 中的顺序。
批量复制与连接
因为目前版本的 SD python api 中,还没有直接调用软件里 ctrl + d 的办法。所以复制节点其实就是创建一个新的相同的节点。
对于这个节点自己所有的 input 属性,记录下所有属性当前的参数,创建新的这个类型的节点,然后把所有的参数都赋值上去就可以了。
学懂前面的部分的话,这里应该是可以自己实现的。这个就当课后作业了。
最后这一部分我要讲的是,像我前面视频教程里那种,带输入输出的节点,批量复制完以后,还要连接在一起,要怎么去做?
最后要实现的结果是,input 节点的 rd,输入到每一个新节点的 rd 上面去,然后每 上一个节点的p0,输入的下一个节点的 p1 里面去。做循环就可以了。
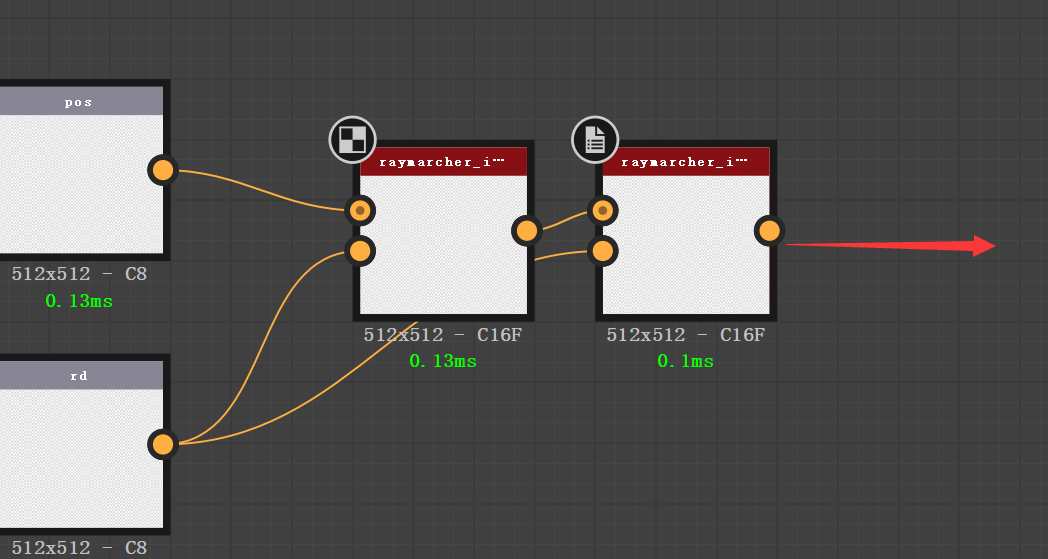
我们现在来详细拆分步骤:
- 知到 input rd节点,这个我们可以通过选中该节点来获取。
- 创建一个新的 raymarcher_iter ,将 input rd 节点的 output,连接到 raymarcher_iter 节点的 rd 属性。
- for 循环。每次循环中,创建一个新的 raymarcher_iter 节点,用上一个 raymarcher_iter 节点的p1,输入到这个新创建节点的 p0 上。返回新创建的 raymarcher_iter 节点,作为下次循环的开始。
- 循环过程中,考虑位置的偏移,每个节点向右偏移150个单位(SD中默认大小的节点为100*100);没10个节点向下移一行,移动150个单位。
现在只要按照我们拆分出来的步骤,每一步都翻译成代码就搞定了。只要逻辑清晰,写代码就可能变得简单。
1)#get rd node
rdNode = UIMgr.getCurrentGraphSelection()[0]
2)#get the file’s absolute path
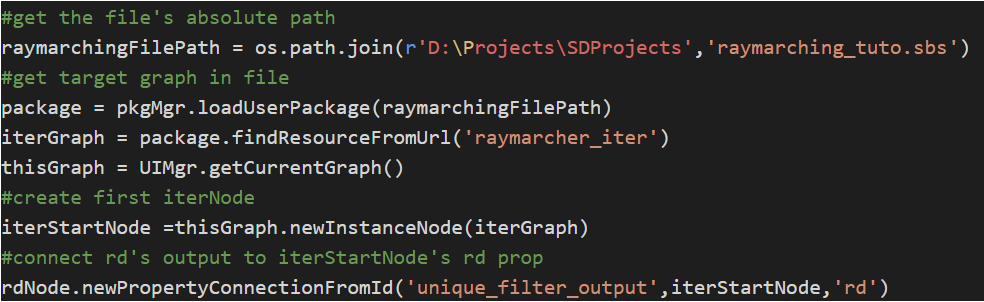
raymarchingFilePath= os.path.join(r’D:\Projects\SDProjects’,’raymarching_tuto.sbs’)
#get target graph in file
package = pkgMgr.loadUserPackage(raymarchingFilePath)
iterGraph = package.findResourceFromUrl(‘raymarcher_iter’)
thisGraph = UIMgr.getCurrentGraph()
#create first iterNode
iterStartNode =thisGraph.newInstanceNode(iterGraph)
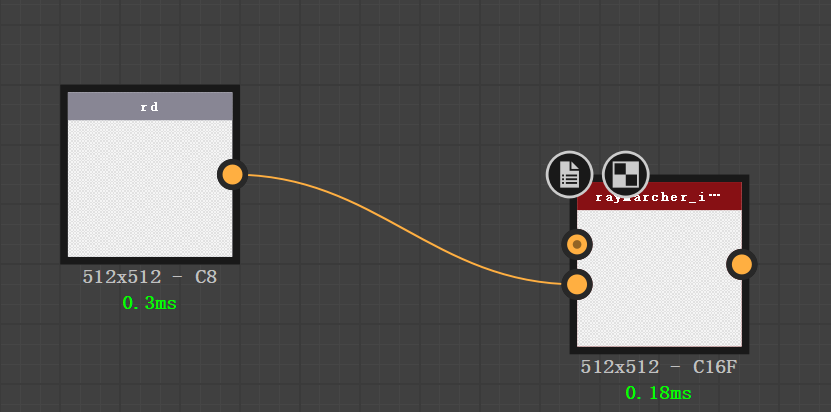
#connect rd’s output to iterStartNode’s rd prop
rdNode.newPropertyConnectionFromId(‘unique_filter_output’,iterStartNode,’rd’)
这时候,就可以实现我们想要的创建新节点并连接的效果
3)
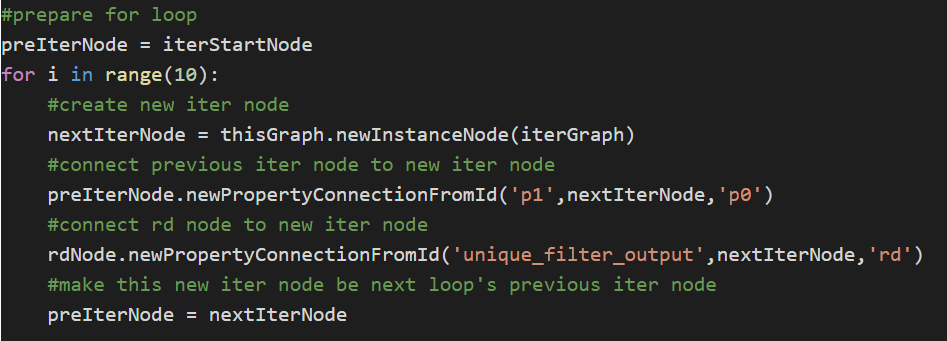
#prepare for loop
preIterNode = iterStartNode
for i in range(10):
#create new iter node
nextIterNode = thisGraph.newInstanceNode(iterGraph)
#connect previous iter node to new iter node
preIterNode.newPropertyConnectionFromId(‘p1′,nextIterNode,’p0’)
#connect rd node to new iter node
rdNode.newPropertyConnectionFromId(‘unique_filter_output’,nextIterNode,’rd’)
#make this new iter node be next loop’s previous iter node
preIterNode = nextIterNode
这部分要创建一个 preIterNode 变量来表示上一个循环完成之后产生的 iter node。因为最开始我们就已经创建了一个 iter node 了,也就是 iterStartNode 这个变量储存的那个节点,在做循环之前,我们就把 iterStartNode 里储存的节点,给到 preIterNode 变量,从理解上认为他是上一次循环(实际上不存在)完成后产生的 iter node。
然后我们在新循环里,创建新的 iter node, 放在 nextIterNode 变量中,讲 pre 和 next 进行属性相连,rd 的节点也连一下。连完之后,我们要把这一次循环中产生的 iter node 节点再赋值给preIterNode,意思是你这个刚刚新创建的节点,将作为老节点经历下一次的循环。
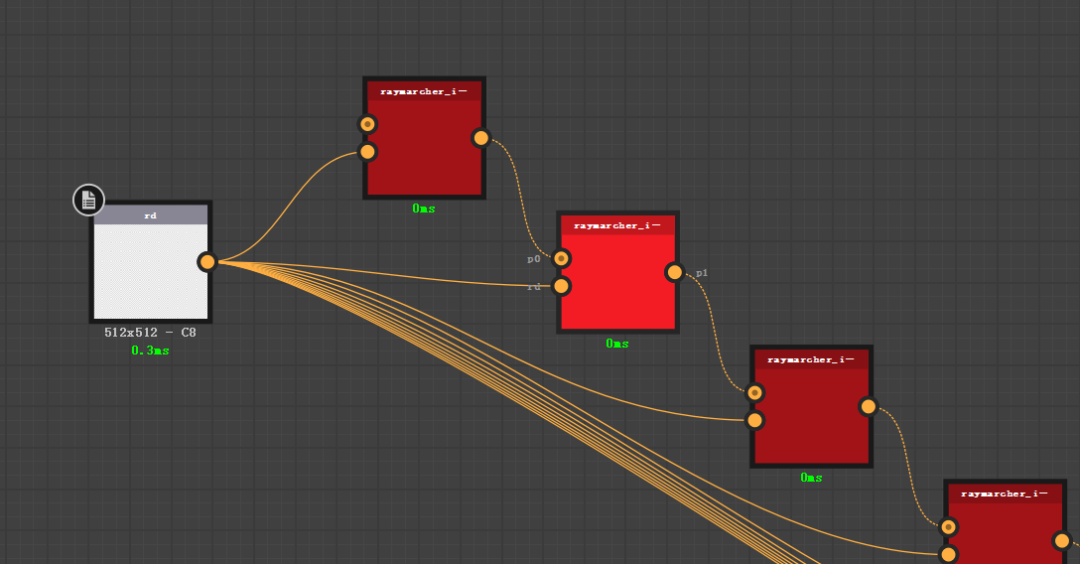
然后这个循环无限进行下去。直到达到我们给定的数值上限。OK~
看一下效果,跟我们期待的一模一样。只是这些节点还没有排布,我手动拉开截图给大家看的这个效果。
4)这一步我们要改一下循环体,让这些节点实现比较好的位置排布。
我们首先要知道这个节点在目标位置的第几行第几列。比如第一行第一列,分别向右和向下移动150个单位,第三行第五列,则是向右移动150*5个单位,向下移动150*3个单位。
算法简单清晰明了。然后算行数和列数的部分,属于小学数学的东西,我应该不需要赘述了。直接放代码,其中j是列数,代表横方向位移;k是行数,代表竖方向位移;计算ceil之前要导入math模块:
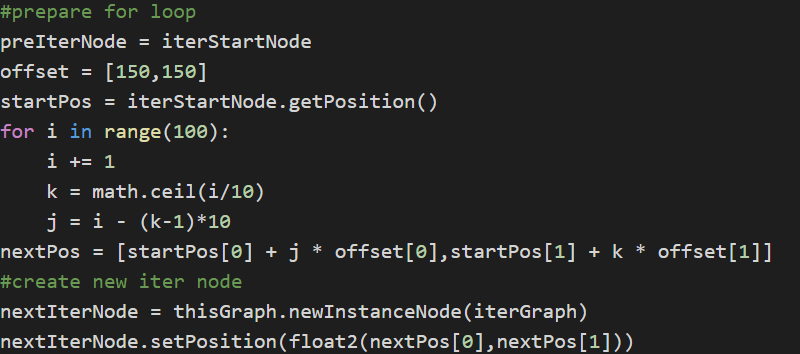
#prepare for loop
preIterNode = iterStartNode
offset = [150,150]
startPos = iterStartNode.getPosition()
for i in range(100):
i += 1
k = math.ceil(i/10)
j = i – (k-1)*10
nextPos = [startPos[0] + j * offset[0],startPos[1] + k * offset[1]]
#create new iter node
nextIterNode = thisGraph.newInstanceNode(iterGraph)
nextIterNode.setPosition(float2(nextPos[0],nextPos[1]))
最后的结果完美,可以根据你自己是否完美主义者来决定要不要删除第一个节点:

然后具体的需求可以看着改代码的一些参数,应该比较简单了。
这一部分内容的全部代码,看着改:
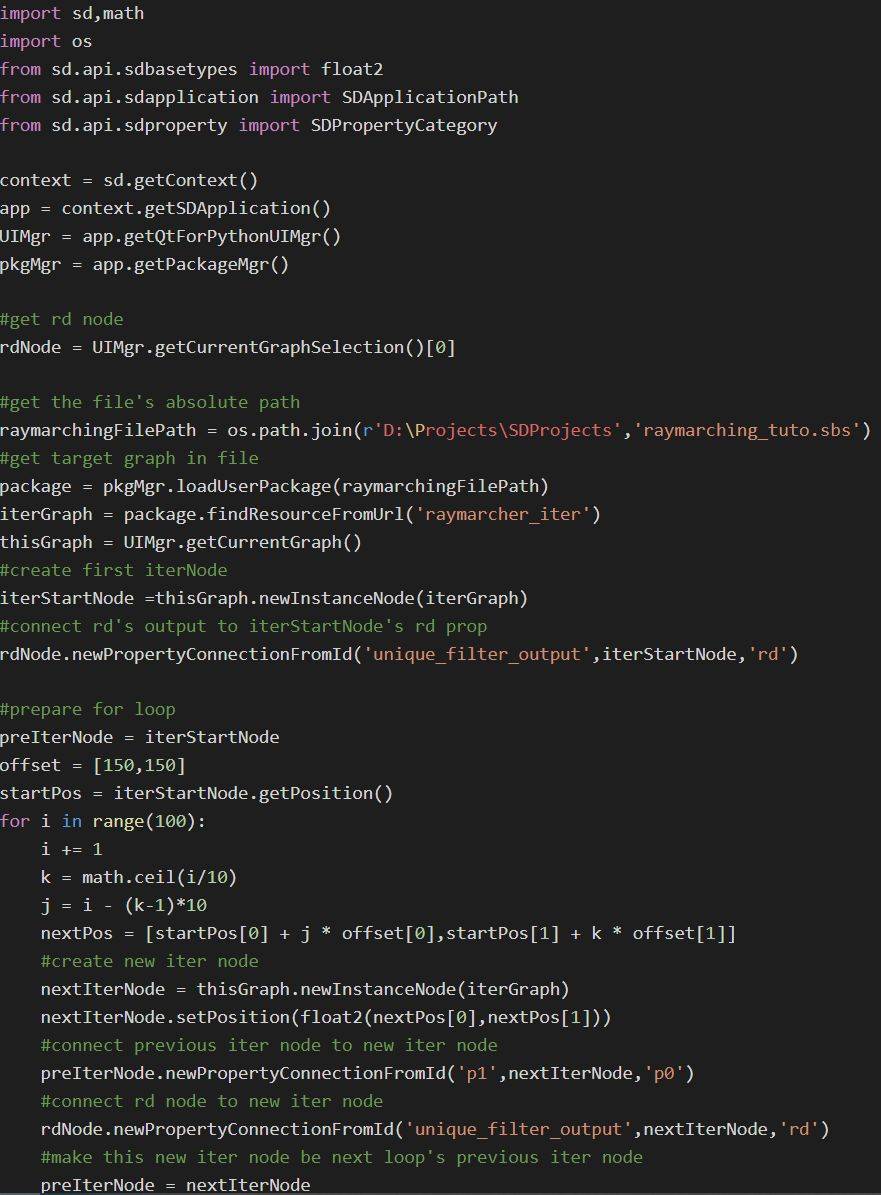
import sd,math
import os
from sd.api.sdbasetypes import float2
from sd.api.sdapplication import SDApplicationPath
from sd.api.sdproperty import SDPropertyCategory
context = sd.getContext()
app = context.getSDApplication()
UIMgr = app.getQtForPythonUIMgr()
pkgMgr = app.getPackageMgr()
#get rd node
rdNode = UIMgr.getCurrentGraphSelection()[0]
#get the file’s absolute path
raymarchingFilePath = os.path.join(r’D:\Projects\SDProjects’,’raymarching_tuto.sbs’)
#get target graph in file
package = pkgMgr.loadUserPackage(raymarchingFilePath)
iterGraph = package.findResourceFromUrl(‘raymarcher_iter’)
thisGraph = UIMgr.getCurrentGraph()
#create first iterNode
iterStartNode =thisGraph.newInstanceNode(iterGraph)
#connect rd’s output to iterStartNode’s rd prop
rdNode.newPropertyConnectionFromId(‘unique_filter_output’,iterStartNode,’rd’)
#prepare for loop
preIterNode = iterStartNode
offset = [150,150]
startPos = iterStartNode.getPosition()
for i in range(100):
i += 1
k = math.ceil(i/10)
j = i – (k-1)*10
nextPos = [startPos[0] + j * offset[0],startPos[1] + k * offset[1]]
#create new iter node
nextIterNode = thisGraph.newInstanceNode(iterGraph)
nextIterNode.setPosition(float2(nextPos[0],nextPos[1]))
#connect previous iter node to new iter node
preIterNode.newPropertyConnectionFromId(‘p1′,nextIterNode,’p0’)
#connect rd node to new iter node
rdNode.newPropertyConnectionFromId(‘unique_filter_output’,nextIterNode,’rd’)
#make this new iter node be next loop’s previous iter node
preIterNode = nextIterNode
以上基本知识都讲完了。学下来的话,满足自己日常工作的一些脚本开发起来应该都是可以实现了。
没找到在编辑显示代码的好方法,可能看着有点难受,手机上几乎没法阅读,主要还是给电脑看的,抱歉。所有代码都有文本,可以直接复制粘贴使用。
最近更新的东西也算得上不少了吧。而且 TI 开打了,兄弟们,我要好好研究一段技术,还要看TI,暂时就不太更技术文章了哈~
相关文章(Related Posts)

